Variance and MTBF
When the data sheet or only available information is MTBF, how much do you know about the variability of the expected time to failure distribution? Not much really.
Do you need to know when to expect the first one percent of failures, 10 percent? Sure, that information is useful when estimating warranty or service costs, also for estimating readiness to go to market. We often are not interesting when the bulk will fail, rather the early small percentages.
If the only piece of information we have is 50,000 hours MTBF (no test data, no field time to failure data, no other information about the estimate other then the MTBF) we should first get more information. Although in some cases, that’s all we have and we have to deal with it.
Variance
We are often interested in the spread of the data, not just the mean value. MTBF is the mean. If we have to assume an exponential distribution then the variance is the square of the MTBF value. Thus the standard deviation is the MTBF also. It’s a feature of the exponential distribution.
Now, I’m not really sure what to make of this fact. For the fan with a mean of 50k hours, minus one standard deviation is zero. This is consistent with Tchebyscheff’s Theorem where at least 3/4’ths of the data is within 2 standard deviation, meaning for the expected failures, at least 3/4 will occur before 100,000 hours. If the units actually follow an exponential distribution then we would expect about 2/3 to fail by 50k hours.
And, this information isn’t very informative for the early time to failure and lower tail values, like 1% or 10%. So, what can we do?
Reliability Function
For the exponential distribution the reliability function is
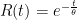
where t is calendar or operating time and theta is the MTBF value.
R is the probability of success at time t. Thus if we want to know how long till 10% of the unit fail, we can set R to 1 – 0.10 or 90% (90% survive or 10% fail) and solve for t, given the MTBF value.
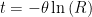
(Assuming I have the algebra correct.)
Ln(0.9) = -0.105 and theta is 50k, we find we would expect 905 of units to survive (or 10% to fail) by 5,268 hours.
Using only the MTBF value, which happens to also be the standard deviation, we can estimate the time till some percentage have failed.
Variance Estimate
Now let’s say we have a set of test data that describes the time to fail for ten units, and all of the units have failed. A quick and very crude way to check if the data is exponential is to estimate the mean and standard deviation. If it’s really an exponential distribution those two values should be the same.
So I tried this idea on a few sets of randomly generated time to failure data based on an exponential distribution and some data based on a normal distribution.
For ten data points generated from an exponential distribution the calculated standard deviation consistently resulted in a value about half of the actual standard deviation of the distribution. For ten data points generated from a normal distribution the calculated standard deviation was actually close to the value used to generated the data.
I then increased the sample size to 100. Using the same basic process of randomly generating time to fail data and calculating the standard deviation, this time found the calculator standard deviation was very close the distribution’s standard deviation (the MTBF value). And the normal standard deviation remained very close to the value used to generate the data.
Since we do not often use the variance or standard deviation for the exponential distribution, this interesting anomaly doesn’t really matter. It just seemed curious to me, that we often work to reduce variation (resulting in less variance describing a data set) and when using only MTBF, even though it’s a given value, since the standard deviation is equal to the mean, there is so little useful information in the exponential standard deviation or variance.
The variance is the second moment of the distribution and something of some use (maybe) to statisticians, and of little practical value to engineers working to reduce variability of finished products.
Fred, you are correct in thinking that the variance of the exponential distribution is generally of little use. It is known (and it’s the reciprocal of the square of the failure rate). I simply point out that the exponential distribution just doesn’t apply in most cases, in that (at least mathematically) there is not a failure rate, but rather an instantaneous rate of occurrence of failures.
At first glance, this may seem like a somewhat anal-retentive comment, but what I think you are after is the idea that in some interval [t1, t2] there is a probability that an item will fail and that it need not be the same in some other interval [t3, t4]. This is important for all kinds of reasons ranging from doing simulations to actually measuring the reliability of a product in service to making valid models.
I’ve had manufacturers tell me with a straight face that (1) the MTBF of a circuit card was 1.8 million hours (over 200 years, if I’ve done the math right), and (2) my field performance isn’t really their problem since the vendor is selling me a product, and not a part of a solution. The reality is that (1) the real replacement rate (all service hours divided by all returns) was a lot less than 1.8 million hours and (2) it was possible to measure both early life and late life replacement rates (they do vary depending on the interval chosen). It turns out that Weibull gives a good fit in this case. While the 63rd percentile of failure times is a meaningful number for Weibull (it’s a summary number, of course), MTBF is meaningless, because it doesn’t exist for Weibull. The same is true (that MTBF doesn’t exist) for products whose failure times follow normal, log normal, and extreme value distributions.
I imagine that Wes Fulton might have some insight here as well.
Hi Paul,
Thanks for the comment. I agree variance for the exponential is not very useful, just a I think MTBF also is not useful (more like misleading).
A primary reason this site exists to expose and explain what MTBF is and is not.
Cheers,
Fred
A nice article, Fred. Shows just how much of an estimate, reliability is at times.