We may use one or more of these when establishing product reliability goals. When tracking performance. When making decisions.
Goals, objectives, specifications, and requirements, are stand-ins for the customer’s experience with the product.
We’re not trying to reduce warranty expenses or shouldn’t be solely focused on just that measure. We need to focus on making decisions that allow our product deliver the expected reliability performance to the customer. Continue reading Reliability is Not Metrics, It’s Decision Making→
We measure results. We measure profit, shipments, and reliability.
The measures or metrics help us determine if we’re meeting out goals if something bad or good is happening, if we need to alter our course.
We rely on metrics to guide our business decisions.
Sometimes, our metrics obscure, confuse or distort the very signals we’re trying to comprehend.
Here are five metric based mistakes I’ve seen in various organizations. Being aware of the limitations or faults with these examples may help you improve the metrics you use on a day to day basis. I don’t always have a better option for your particular situation, yet using a metric that helps you make poor decisions, generally isn’t acceptable.
The Variety of Statistical Tools to Support Your Decision Making
My wife and I moved to a new home last year. We have yet to organize our tools.
The bedroom and kitchen are now organized. We, for the most part, can find the sweater or pan that we’re seeking.
No so for our tools in the shop. We have an assortment of hand tools for painting, home maintenance, yard work, and woodworking. In our previous home, we had the tools on pegboards, on shelves, in cabinets. We could find the right tool for the job at hand quickly. We’ve avoided the tool aisle at the hardware store recently, as we were sure we had the tool we need in the jumbled mess in our garage already. Still haven’t found it, though.
Have you noticed the number of statistical tools available? It’s like visiting a well-stocked tool store. There are basic tools like trend charting and advanced tools like proportional hazard models. Let’s explore the available tools a little so you can quickly find the right tool for the question or problem you are facing today. Continue reading The Variety of Statistical Tools→
Nearly everyone I’ve ever met doesn’t like their toaster to fail.
It will, and that is a bummer, as the quick and easy way to warm up the morning toast will be thwarted.
Failures happen. As reliability engineers, we know that failures happen. Helping others to identify potential failures, to avoid failures or to minimize failures is what we do best.
In college, Mechanics was a required class from the civil engineering department. This included differential equation.
Luckily for me, I also enjoyed a required course called analytical mechanics for my physics degree. This included using Lagrange and Hamiltonian equations to derived a wide range of formulas to solve mechanisms problems.
In the civil engineering course, the professor did the derivation as the course lectures, then expected us to use the right formula to solve a problem. He even gave us a ‘cheat sheet’ with an assortment of derived equations. We just had to identify which equation to use for a particular problem and ‘plug-and-chug’ or just work out the math. It was boring. Continue reading Math, Statistics, and Engineering→
One technique to calculate a product’s MTBF is to count the number of failures and divide into the tally of operating time.
You already know, kind reader, that using MTBF has its own perils, yet it is done. We do not have to look very far to see someone estimating or calculating MTBF, as if it was a useful representation of reliability… alas, I digress.
Seriously, while out walking, listening to a podcast, and playing Pokemon Go, found an open house to view. A week later our offer was accepted and next week we close.
I would not have been out walking that Sunday afternoon if not out playing Pokemon Go.
A Few Simple Ideas to Improve Your Reliability Program
Spending too much on reliability and not getting the results you expect? Just getting started and not sure where to focus your reliability program? Or, just looking for ways to improve your program?
There is not one way to build an effective reliability program. The variations in industries, expectations, technology, and the many constraints, shape each program. Here are three suggestions you can apply to any program at any time. These are not quick fix solutions, nor will you see immediate results, yet each will significantly improve your reliability program and help you achieve the results you and your customers expect. Continue reading 3 Ways to Improve your Reliability Program→
In today’s complex product environment becoming more and more electronic, do the designers and manufacturers really understand what IS Reliability ??
It is NOT simply following standards to test in RD to focus only on Design Robustness as there is too much risk in prediction confidence, it only deals with the ‘intrinsic’ failure period and rarely has sufficient Test Strength to stimulate failures. Continue reading What is Reliability?→
Failure Happens – It Is What Happens Next That Matters
One of the benefits of reliability engineering is failure happens.
Nothing made, manufactured, or assembled will not fail at some point. It is our desire to have items last long enough that keeps us working. Since failures happen, our work includes dealing with the failure.
Not My Fault
Years ago while preparing samples for life testing at my bench, I heard an ‘eep’ or a startled sound from a fellow engineer. It was quickly followed by an electrical pop noise and a plum of smoke.
Something on the circuit board she was exploring had failed. With a pop and smoke. She didn’t move.
At this point, my initial amused response turned to concern for her safety. She was fine, just startled as the failure was unexpected. She quickly claimed it wasn’t her fault.
It was her design, she selected and assembled the parts, and she was testing the circuit. Yet, it wasn’t her fault. She did not expect a failure to occur (a blown capacitor – which we later discovered was exposed to far too much voltage), thus it was not her fault.
We hear similar responses from suppliers of components. It must have been something in your design or environment that caused the failure, as the failure described shouldn’t happen. It’s not expected.
Well, guess what, it did happen. Now let’s sort out what happened and not immediate assign blame for who’s fault it is.
The ‘not my fault’ response so a failure is not helpful. Failures are sometimes the result of a simple error and quickly remedied. Other are complex and difficult to unravel. The quicker we focus on solving the mystery of the cause of the failure, the quicker we can move on to making improvements.
Warranty
With possibly too many ‘not my fault’ responses, laws now enjoin the manufacture of products to stand behind their product. If a failure occurs, sometimes within specific conditions, the customer may ask for a remedy from the supplier.
If failures did not happen there would be no such thing as a warranty.
A warranty is actually a legal obligation, yet has turned into a marketing tool. A long warranty implies the product is reliable and by offering a long warranty the manufacturer is stating they are shifting the risk of failure to themselves.
A repair or replacement is generally not adequate recompense for a failure, yet it provides some restitution. In most cases, it only provides peace of mind, if the item doesn’t fail.
The warranty business has become an industry in of itself. Selling, servicing, and honoring warranties is something that others can deal with outside your organization. The downside is the lack of feedback about failure details so you can affect improvements. A manufacturer shouldn’t hide behind their warranty policy, nor ignore the warranty claim details. It is one-way a customer can voice their expectations concerning product reliability. You should listen.
Repair services
My favorite outsourced repair service story involved a misguided payment structure.
If you pay a repairman based on the value of the components replaced, they will likely always replace the most expensive components. If the repair is accomplished by resetting a loose connector, nothing is replaced, and the repairman is not compensated for the diagnostic work and effective repair. If he instead immediately replaced the main circuit board, and in the process reseating most of the connectors, the repair is fast, effective, and he is handsomely rewarded.
See the problem?
When a failure occurs, it may be natural to offer a repair service as the remedy. It should be quick (not a two-week wait as with my local cable company to restoring a fallen line), and efficient for all parties involved. For the owner of the equipment, we want the functionality restored as quickly as possible and cost effectively as possible. For the manufacture of the equipment, we want cost effectiveness, plus the knowledge concerning the failure.
Does your repair service provide for the needs of both parties as well as the repair technician?
Fail safe
Sometimes when a failure occurs nothing happens. We might not even notice the failure occurs. Other times the product simply goes ‘cold’ or a function is lost. Nothing adverse, no pop or smoke, occurs.
We call this failing safe. It’s more complicated than my simple explanation, yet it is the desired repose to a failure. The product itself should not create more damage, cause harm, place someone in peril. It should fail safely and preferably quietly.
If the ignition falls from the ignition switch, which may be considered a failure to retain the key within the switch, the driver should not lose control of the vehicle. This is in part a safety feature, yet is also a common expectation that the failure of a system should not create other problems.
Failure containment is related.
How does your product fail? Safely?
Maintenance
For some failures, such as the degradation of lubricants, we perform maintenance. When the brake pads or tire tread wears to marginally safe level we replace the brake pad or tire. If we can anticipate the failure pattern we perform preventive maintenance.
Creating a maintainable piece of equipment is one response to failures. It allows creating complex equipment with failure prone elements. Through maintenance, we are able to restore the system to operation or avoid unexpected downtime. If failures didn’t occur, we wouldn’t need maintenance.
We have some control over the nature of the maintenance activities. For some types of failures, we can only execute corrective maintenance. For others, we can use preventative methods. The idea is to anticipate and avoid the widest range of failures through effective maintenance practices, that remains cost effective.
Adding maintenance practices in response to system failures is not the duty of the owner of the equipment. It is a design function to anticipate the system failures that may occur and devise the appropriate maintenance plan to thwart unwanted failures from occurring. The two parties actually have to work together to make this work well.
Expectations
When I buy a product, I know that some proportion of products like the one I just purchased will failure prematurely. I just do not want or desire mine to fail. My expectation is the one I select at the store is a good one. It won’t let me down, stranded, or injured. That is my expectation.
When a failure does occur and I value the functionality the product provides I will want to restore the unit via repair or replacement, sometimes via a service contract or warranty or repair center. To a large degree, my expectation is after a failure all will go well.
As the manufacture of products, when a failure occurs, your expectations may include learning from the failure to make improvements. Or it should.
We know we cannot anticipant nor avoid every failure that may occur. The expectation on both sides is to make robust and dependable products that provide value for all involved. When that approach fails, we fail.
Failure Happens
In response to a failure, it’s how the product, customer, and manufacture responds that matters. A simple failure can turn into a disaster for all involved. Or the failure can provide insights leading to breakthrough innovations and new opportunities.
Are the Measures Failure Rate and Probability of Failure Different?
Failure rate and probability are similar. They are slightly different, too.
One of the problems with reliability engineering is so many terms and concepts are not commonly understood.
Reliability, for example, is commonly defined as dependable, trustworthy, as in you can count on him to bring the bagels. Whereas, reliability engineers define reliability as the probability of successful operation/function within in a specific environment over a defined duration.
The same for failure rate and probability of failure. We often have specific data-driven or business-related goals behind the terms. Others do not.
If we do not state over which time period either term applies, that is left to the imagination of the listener. Which is rarely good.
Failure Rate Definition
There at least two failure rates that we may encounter: the instantaneous failure rate and the average failure rate. The trouble starts when you ask for and are asked about an item’s failure rate. Which failure rate are you both talking about?
The instantaneous failure rate is also known as the hazard rate h(t)

Where f(t) is the probability density function and R(t) is the relaibilit function with is one minus the cumulative distribution function. The hazard rate, failure rate, or instantaneous failure rate is the failures per unit time when the time interval is very small at some point in time, t. Thus, if a unit is operating for a year, this calculation would provide the chance of failure in the next instant of time.
This is not useful for the calculation of the number of failures over that year, only the chance of a failure in the next moment.
The probability density function provides the fraction failure over an interval of time. As with a count of failures per month, a histogram of the count of failure per month would roughly describe a PDF, or f(t). The curve described for each point in time traces the value of the individual points in time instantaneous failure rate.
Sometimes, we are interested in the average failure rate, AFR. Where the AFR over a time interval, t1 to t2, is found by integrating the instantaneous failure rate over the interval and divide by t2 – t1. When we set t1 to 0, we have

Where H(T) is the integral of the hazard rate, h(t) from time zero to time T,
T is the time of interest which define a time period from zero to T,
And, R(T) is the reliability function or probability of successful operation from time zero to T.
A very common understanding of the rate of failure is the calculation of the count of failures over some time period divided by the number of hours of operation. This results in the fraction expected to fail on average per hour. I’m not sure which definition of failure rate above this fits, and yet find this is how most think of failure rate.
If we have 1,000 resistors that each operate for 1,000 hours, and then a failure occurs, we have 1 / (1,000 x 1,000 ) = 0.000001 failures per hour.
Let’s save the discussion about the many ways to report failure rates, AFR (two methods, at least), FIT, PPM/K, etc.
Probability of Failure Definition
I thought the definition of failure rate would be straightforward until I went looking for a definition. It is with trepidation that I start this section on the probability of failure definition.
To my surprise it is actually rather simple, the common definition both in common use and mathematically are the same. There are two equivalent ways to phrase the definition:
The probability or chance that a unit drawn at random from the population will fail by time t.
The proportion or fraction of all units in the population that fail by time t.
We can talk about individual items or all of them concerning the probability of failure. If we have a 1 in 100 chance of failure over a year, then that means we have about a 1% chance that the unit we’re using will fail before the end of the year. Or it means if we have 100 units placed into operation, we would expect one of them to fail by the end of the year.
The probability of failure for a segment of time is defined by the cumulative distribution function or CDF.
When to Use Failure Rate or Probability of Failure
This depends on the situation. Are you talking about the chance to failure in the next instant or the chance of failing over a time interval? Use failure rate for the former, and probability of failure for the latter.
In either case, be clear with your audience which definition (and assumptions) you are using. If you know of other failure rate or probability of failure definition, or if you know of a great way to keep all these definitions clearly sorted, please leave a comment below.
Are Your Reliability Engineering Technical Skills Good Enough?
How do you know? How would you know?
There is a lot to know concerning the technical aspects of reliability engineering. From calculating summary statistics to discovering the root cause of a failure, the body of knowledge you should master as a reliability personal is expansive. Continue reading Are Your Reliability Engineering Technical Skills Good Enough?→
 Reliability is Not Metrics, It’s Decision Making
Reliability is Not Metrics, It’s Decision Making 5 Ways Your Reliability Metrics are Fooling You
5 Ways Your Reliability Metrics are Fooling You The Variety of Statistical Tools to Support Your Decision Making
The Variety of Statistical Tools to Support Your Decision Making Two people have shaped how I guess an answer.
Two people have shaped how I guess an answer.
 Math, Statistics, and Engineering
Math, Statistics, and Engineering When Do Failures Count?
When Do Failures Count? Reliability Goal and Confidence
Reliability Goal and Confidence Walking, Playing and Bought a House
Walking, Playing and Bought a House A Few Simple Ideas to Improve Your Reliability Program
A Few Simple Ideas to Improve Your Reliability Program Guest Post by Martin Shaw
Guest Post by Martin Shaw Failure Happens – It Is What Happens Next That Matters
Failure Happens – It Is What Happens Next That Matters Are the Measures Failure Rate and Probability of Failure Different?
Are the Measures Failure Rate and Probability of Failure Different?
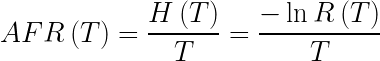
 Getting Enough of the Right Professional Development
Getting Enough of the Right Professional Development Are Your Reliability Engineering Technical Skills Good Enough?
Are Your Reliability Engineering Technical Skills Good Enough?