Reliability Growth and MTBF

Really? Is MTBF the only way to work with reliability growth?
Received this question via LinkedIn (feel free to connect with me there) and hadn’t given it much thought before. I am familiar with a few growth models and regularly have seen MTBF in use. Thus discounted the modeling as an approach of little interest to me or my clients.
MTBF measures the inverse of the average failure rate, when in many cases we really want to know about the first or tenth percentile of time to failure. Measuring and tracking the average time to failure provides little information about the onset of the first few failures.
Reliability Growth Models
Did just a quick check of common reliability growth models and found a few in the NIST Engineering Statistics Handbook http://www.itl.nist.gov/div898/handbook/apr/section1/apr19.htm .
The Homogeneous Poisson Process (HPP) when the failure rate is constant over the time period of interest. This relies on the exponential distribution and the assumption of a stable and random arrival of failures, which is almost always not true (in my experience). It’s a convenient assumption as it makes the math a lot simpler, yet provides only a crude model and poor results.
The Non-Homogeneous Poisson process (NHPP) Power Law and Exponential Law models provide information based on the cumulative number of failures over time. These models rely on the notion that any system has a finite number of design errors that once resolved create a system that has a HPP behavior.
Duane Plot provides a graphical means to show cumulative failures over time. When the arrival of failures slows the curve decreases in slope effectively bending over. This provides a means to estimate the final failure rate (average unfortunately).
What I use instead
Given my dislike of all things MTBF, I’ve not used these model to estimate MTBF. Instead stay with the Duane plot and graphically track when the team is finding and fixing enough faults in the design.
I also tend to use reliability block diagrams (RBD) with each block modeled with the appropriate reliability distribution. For a series model then all we need to do is multiple the reliability value from each block for time t (say warranty period, or mission time, etc.) to estimate the system reliability at time t.
For complex systems with some amount of redundancy the RBD does get a bit more complicated. For very complex systems with degraded modes of operation or significant repair times then use Petri Nets or Markov Models to properly model.
In the vast majority of cases a simple RBD is sufficient to capture and understand the reliability of a system. This allows the team to focus on improving weak areas and reduce uncertainty though improving reliability estimates. An RBD does not require nor assume an exponential distribution and the math is easy enough to manage, often even in your favorite spreadsheet.
Summary
Reliability growth starts with model of the estimated number of failures over a time period. Testing then provides a value for that estimate. This does not require the use of MTBF, so instead of assuming a constant failure rate, focus on the failure mechanisms and use a simple RBD to build a system model. The reliability growth is the result of identifying areas for improvement and doing the improvement. RBD, in my experience, provides a great way to communicate with the team where to focus improvements.




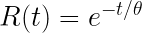
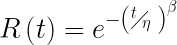

 The basic question of ‘How long should it last?” may be the first question you consider related to reliability of your product or production equipment. Ideally we would like to create a product that will never fail for our customers, or a set of equipment that just keeps running.
The basic question of ‘How long should it last?” may be the first question you consider related to reliability of your product or production equipment. Ideally we would like to create a product that will never fail for our customers, or a set of equipment that just keeps running. 