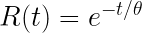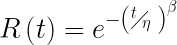Time to move on from Mean Time Between Failure (MTBF) and Mean Time To Failure (MTTF)
Guest Post by Dan Burrows
Reliability, Quality, Six Sigma, & Performance Improvement Leader

rachel opens reliable design of medical devices – a textbook that nobody else would dare to read.
The reliability profession has historically embraced two metrics, Mean Time Between Failure (MTBF) for repairable items and Mean Time To Failure (MTTF) for non-repairable items. They did this mostly out of convenience when dealing with large populations such as fleets of vehicles to address the random failures that were being experienced and to make the mathematics simple. And this approach worked fairly well before better approaches came into play. But this approach also worked fairly well because other reliability and maintainability practices were also enforced, namely planned/preventive/scheduled maintenance whereby serviceable items were serviced to keep them in proper operating condition, wearable items were replaced or restored, life limited items were replaced and good operating and failure data was kept. Without enforcing the maintainability and good data side of this, MTBF and MTTF become misleading at the least and dangerous in many cases.
Thus, MTBF or MTTF could address the flat portion of the traditional “Bathtub Curve”. Proper maintenance could address the wearout/life limit portion of the bathtub curve. And screening and run in/burn in could mitigate the early failure portion of the bathtub curve.
Traditional Bathtub Curve
So, there are four big mistakes that people often make with MTBF and MTTF related to the bathtub curve:
Mistake #1: MTBF and MTTF are erroneously used as projections of product useful life.
Mistake #2: MTBF and MTTF assume a constant failure rate during the useful life of the item.
Mistake #3: MTBF and MTTF are given an assumption of high likelihood that the product will make it to the value.
Mistake #4: MTBF and MTTF data is assumed to be good and current.
Let’s take a closer look at these four big mistakes…
Mistake #1: MTBF and MTTF are erroneously used as projections of product useful life
Let’s take a common example. Electrolytic capacitors can have MTBF (actually should be stated MTTF since they are not repairable) values of 108 (one hundred million) or 109 (one billion) hours. If one were to divide these numbers by hours in a year to project useful life, this would result in a useful life of 11,415 to 114,155 years! In reality, electrolytic capacitors, if derated and applied properly typically have a useful life of 10 to 20 years. This is because the electrolyte in electrolytic capacitors dissipates, drying up the capacitor, causing significant degradation in performance (capacitance, leakage current, or ESR) or outright open or short failure. This doesn’t mean that electrolytic capacitors are necessarily bad, just that they don’t live for 10,000+ years.
So, how should MTBF and MTTF be used? They should be used as indicators of failure rate during the useful life of the product. So, you take the MTBF or MTTF value and invert it, dividing 1 by it. This gives you the expected failure rate per operating hour for the product during its useful life. So, our electrolytic capacitors that have a MTBF of 108 (one hundred million) or 109 (one billion) hours actually have an expected failure rate of 1 to 10 x 10-9 failures per operating hour. It is possible that they will be very reliable during their 10 to 20 year useful life, but then they are dried out and done.
Using MTBF or MTTF values as projections of product useful life is extremely misleading and will probably get you laughed out of your job. Think about that before you improperly use MTBF or MTTF to claim that a product will last 10,000 years. Somebody may ask for a warranty that long. In writing.
Mistake #2: MTBF and MTTF assume a constant failure rate during the useful life of the item.
Many products do not exhibit a constant failure rate. Especially if the early failures were not mitigated and the product was not properly maintained. MTBF and MTTF only address the portion of the product’s failure population that arise out of random chance and apply a very simplistic “mean” by dividing the total operating time of the product population by the total number of failures. This is then made to look scientific by then stating that this is an exponential distribution whereby the failures that arose in the population were evenly distributed with no proof of even distribution. But the world is not random and failures do not arrive at a constant rate over the life of the product or product population. Most product failures happen in non-exponential distribution, non-random patterns for identifiable reasons.
Let’s say you have a product population of five products with the following failure times: 98, 99, 100, 101, 102. If you use the standard MTBF averaging, you have a MTBF of 100 hours. But these failures are not randomly distributed with a constant failure rate. They are clustered around 100 hours and there is probably an identifiable reason why.
Let’s say you have a product population of five products with the following failure times: 10, 10, 10, 235, 235. Again, if you use the standard MTBF averaging, you have a MTBF of 100 hours. It is obvious that there is something going on that caused three products to have a very short life and two products to have a much longer life. Either way, there is probably an identifiable reason why three products failed early and two lived much longer.
Assuming a constant failure rate and using simple averaging of failure times to come up with MTBF or MTTF values is lazy at best. Don’t be lazy, investigate failures to find root causes. These root causes will help you determine how to design products to eliminate the failure, mitigate against the failure, or perform proper preventive and predictive maintenance to avoid the failure.
Mistake #3: MTBF and MTTF are given an assumption of high likelihood that the product will make it to the value.
Even if we do mitigate early life failures and perform proper maintenance, most people assume that the MTBF or MTTF is a value with high statistical likelihood like a B10 life (the point at which 10% of products fail and 90% continue to survive) for bearings. Due to the constant failure rate assumption and underlying statistical distribution, MTBF and MTTF are actually the point at which 63% of products would have failed and only 37% survive. Some high likelihood, — recall that MTBF is the inverse of the failure rate, not a duration.
You can check the math yourself. The probability of survival of a product following the constant failure rate of the exponential distribution is e-(1/MTBF)(Operating Time). So, a product with a MTBF of 200,000 hours will have a probability of survival of e-(1/200,000)(200,000) or 37%.
Assuming MTBF and MTTF are high likelihood projections is actually almost the exact opposite of how the math really works out. Use MTBF and MTTF with high caution, not high trust.
Mistake #4: MTBF and MTTF data is assumed to be good and current
Even if you make it past the first three mistakes, this fourth mistake usually throws a wrench in MTBF and MTTF because many of the prediction models and prediction tools being sold are based on outdated information and outdated technologies. One example of this is using a MTBF prediction model for a flash memory device. Most of the data behind prediction tools stopped getting updated when the United States Defense Department transitioned to commercial off the shelf acquisition practices and stopped funding the collection of component operating and failure data. One example is many models for flash memory include devices that have 256K or 512K capacity while the world has moved way past this.
Assuming that the information in prediction models and tools is good and current may lead you to making extremely erroneous predictions of MTBF and MTTF. If you are going to predict MTBF or MTTF, you need to either have collected the operating and failure data yourself and analyzed it properly or make sure that component suppliers are providing good data.
Time to move on…
MTBF and MTTF may have had a brief time in the spotlight of reliability when items were screened for early defects and maintained properly, good data was kept, and people didn’t know how to or didn’t know better about uncovering root causes of failures and designing them out or mitigating them. But that past is past. It is time to move on from MTBF and MTTF to more effective methods to drive reliability.
Maybe you are one of the lucky ones who deal with large product populations, products are all properly maintained, and you keep good data so the MTBF and MTTF math still holds.
Good for you.
Most of us live in a demanding world with demanding customers and demanding bosses and tight schedules and limited resources. Customers don’t want to hear about averages that have low confidence levels, they expect the product they bought to live its expected usage life. Bosses don’t want to hear about the huge number of product samples needed to test and huge amount of field data needed to statistically derive the proper failure distribution analysis, they want to know why the product has not launched yet.
Reliability professionals in today’s world have to understand more and guide product teams to:
Design for Reliability for proper application, design margin, and derating.
Design for Maintainability to address issues that must be mitigated by maintenance when the needed product life reliability cannot be achieved without maintenance actions.
Failure Mode and Effects Analysis (FMEA) and Fault Tree Analysis (FTA) to determine the risks to the product based on severity, occurrence, and detection to drive actions to drive down risk before it becomes realized.
Reliability Testing to aggressively test and discover failures, at what point failures occur, and how much reliability margin the product will have to drive actions to correct the weak links in the design.
Design for Manufacturability to preserve the designed in reliability of the product during its manufacture.
Get Good Data from your own test and field history and supplier data you can trust instead of relying on generic and often outdated and obsolete prediction data. Data for your products in your customer’s hands tells you the real story of how your products are actually performing in their actual (and sometimes surprising) usage applications and operating environments.